Before we dive into the topic at hand, I just wanted to give you a heads up that this blog post is a recap of my presentation at syd<video> on June 15, 2023.
During the presentation, I talked about how last mile monitoring and crowd sourced testing can help you uncover blindspots and broaden the range of monitorable elements in your system and business.
I’m sure that most of the people reading this have varying degrees of network monitoring and analytics set up in their cloud or on-prem environment.
I want to quickly discuss how you are able to improve your existing stack further by integrating some different types of network monitoring that are usually outside of your traditional stack.
I’m a Senior fullstack developer by trade, with some background in DevOps and Cloud Engineering. However, I have been interested in tech since I was 9.
I built an online multiplayer game at a young age, built some homebrew applications for the Nintendo DS and have a keen interest in Cryptography.
After highschool, I went directly to creating iOS applications for a law firm in Sydney and then begun studying IT at University. While at university, I begun work at some legal tech firms where I built backend services and APIs, did a bit of frontend and then moved on to creating Kubernetes clusters and focused on creating Highly Available cloud environments across multiple cloud providers.
Bitping is the manifestation of my dissatisfaction I had with traditional cloud based monitoring solutions in certain scenarios. My partners and I participated in a hackathon in 2019 to build a product based on micropayments and thus Bitping was born, we decided to merge the concept of uptime testing with crowdsourced networking data and out of that original project, the true potential of Bitping was revealed to us as we built our company.
So when building any of my monitoring stacks, I always have 3 concepts in mind. Measure, Monitor and Mitigate. Each of these concepts feeds into the following to help you stay on top of the status of your systems, keep everyone involved informed and formulate plans to prevent unforseen downtime in the future.
Your tools should be constantly measuring as many metrics in your stack as possible, providing you with a comprehensive overview of your systems while constantly identifying and aggregating performance issues and anomalies. The reason you need to collect all this in depth information is so that you can use the insights to determine what constitutes a performance issue or an outage that a stakeholder should be aware of.
Monitoring your stack involves taking the collected measurement information, deriving some of these insights and prioritising them. You will quickly find that some things need acting on immediately and other insights will be need to be collated for reports in the future.
Mitigation on the other hand falls into 2 different categories. You could be setting up live mitigation techniques when you detect anomalous traffic or user behavior, maybe you detected an excess of HTTP 500 responses codes coming from one of your servers, a live mitigation technique would be to reroute traffic to a healthier box.
There is also proactive and retrospective mitigation. When you’ve collected enough data to highlight insights in to issues or bottlenecks in your system its much easier to put toghether a business plan to improve your system reliability, this has the flow on effect of potentially increasing sales & customer satisfaction all the while helping your system scale in the future.
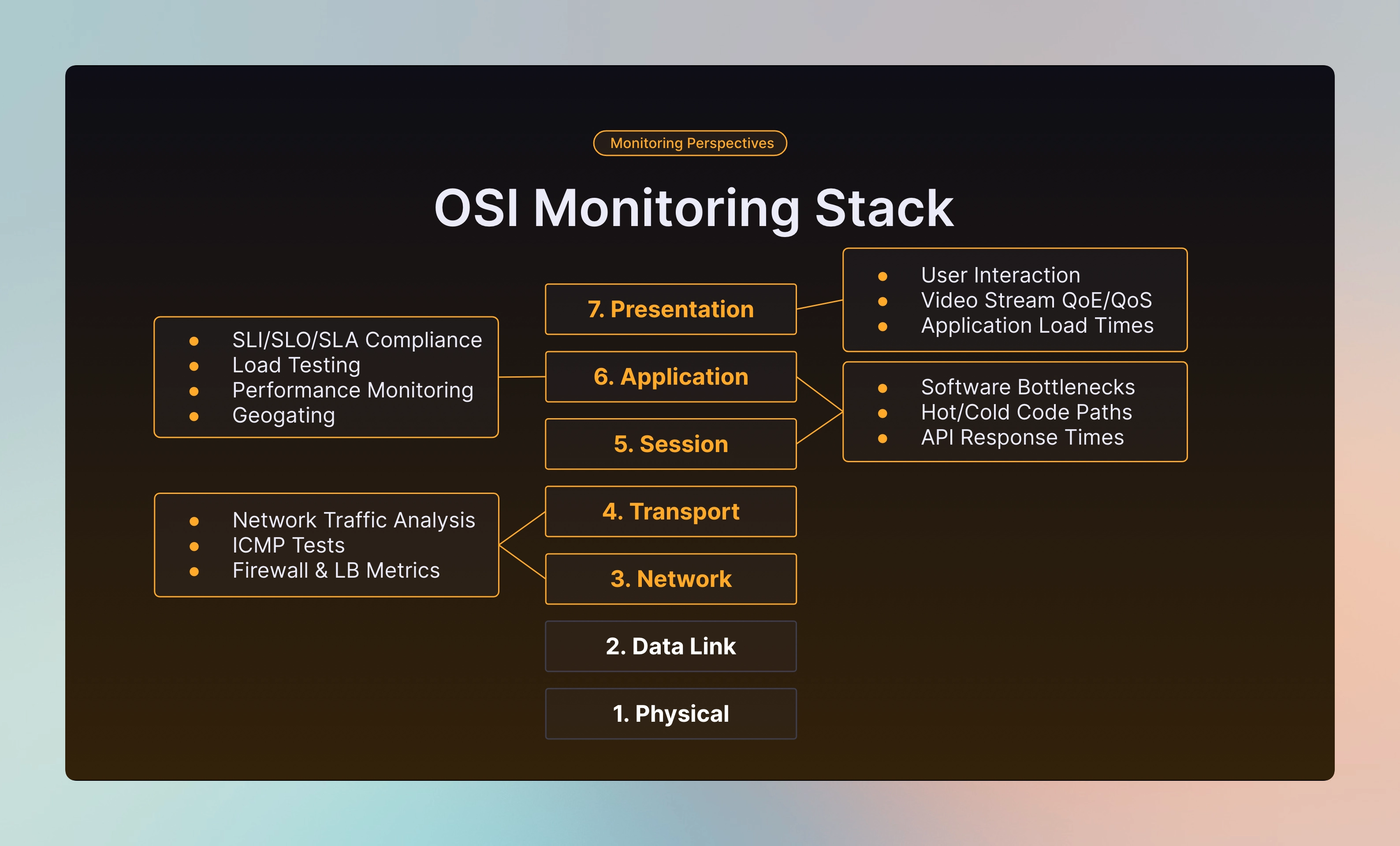
Part of understanding how to go about building your monitoring stack is understanding which layers of the OSI stack you are targeting, this will help you build up a comprehensive monitoring suite. We will mainly be focusing on the network layer and above however just for completion’s sake, I’ll go into the bottom two briefly.
When implementing monitoring for the Physical and Data Link layers you’ll be mainly thinking about server hardware monitoring, things such as CPU Utilisation, RAM usage, Disk IO, Network throughput etc.
At the Network and Transport Layers we start delving into analytics looking at your inbound and outbound connections to your servers, you’ll be thinking about doing Network Traffic and Packet Analysis, recurring ICMP/Ping tests to your servers to ensure they’re always reachable and within a reasonable amount of time and then Firewall and Load Balancer logs and metrics along with Intrusion Detection and Prevention systems.
As you get higher up the stack, you get closer to your customers and because of this, a lot more of what you end up monitoring is related to user interactions and as such you want to be focused on things such as Performance monitoring, evaluating how your servers perform under load, you’ll be benchmarking your hot/cold code paths to identify bottlenecks in your system. Depending on your business, you might also be keeping track of your SLA Compliance. You may even find that some of your clients are monitoring your own services to ensure that you are sticking to your contract.
At the very top, I like to think about this as the webpage level or the thin client level, you will be getting direct feedback from your customers in terms of User Interaction tracking, monitoring Video Stream Quality of Service and Quality of Experience and ensuring that your application load times are as snappy as possible. Up at this level, it’s the hardest to generate insights about your customers, and as such you need the right tools for the job, this is where Last Mile Monitoring and Crowdsourced Testing comes in.
So after all that you might be thinking “I dont have any issues collecting user interactions, I have a RUM tool!” and while a RUM tool can provide very good insights for customers that are using your website, it completely fails to catch intermittent outages and users that are either on internet connections that block your scripts or web browsers that block your RUM scripts. As more and more browsers enable Ad blocking and Tracker blocking by default, you will find that you will be lacking more and more insights about your users.
Last mile monitoring tools on the other hand do not have this issue, traditionally Last Mile monitoring information is collected from a DSLAM or more recently, some systems like Australias NBN’s Fibre to the Node boxes can collect this information as well. Because these last mile metrics are actually run via the ISP, they completely circumvent issues such as Adblocking and will still provide information about your potential customers connection during outages.
At the end of the day as a business you want to be posing a question “Can my customers access my website and user my service?“. Traditional monitoring tools will provide you with information about users that can access your website but are effectively blind to customers that cannot. This means that your metrics are actually at risk of over representing the success rate of customers accessing your business. Last Mile Monitoring comes along to attempt to remedy that by providing information to you from right up to before your customers router.
You might be thinking, “How is that the last mile? Seems like there is a little bit more that is missing - the connection from the ISP to the actual end user’s device” and you would be correct. Last Mile Monitoring is really “Almost the entire last mile monitoring” and because of this, there are still insights that are going missing. Crowdsourced testing is a methodology where a large set of people around the world run network testing tooling and provide the same insights that would be generated from Last Mile Monitoring but actually running on the end user’s device, be it a smartphone, tablet or home computer.
One of the biggest benefits to Crowdsourced Testing is that because of the large array of devices, internet connection types and software installed, you can really get an actual representation of your customer base. For example, you could be alerted to the fact that someone in North Sydney on TPG, using Firefox on their iPhone are unable to load your webpage on a 120 megabit internet connection.
Another benefit of Crowdsourced testing is the range of new issues that can be detected. For example, DNS Cache Poisoning attacks can be very easy to detect now, giving you the upper hand in alertness when your customers are being targeted for Phishing scams. You might also collect information that a large majority of internet users are unable to access your website on certain web browsers or that your application does not load on specific operating systems.
So by now, it should be clear that depending on what part of the OSI stack you are monitoring, each tool has blind spots. Last Mile Monitoring cannot provide insights to your end user devices, only to their internet connections. Crowdsourced Testing can identify issues with internet connections and end user devices, however can not provide internal network metrics. Traditional Monitoring Tools can provide metrics about hardware and services that you own, however have limited use when collecting outages from a customers end.
As we navigate through the complex world of network monitoring, it becomes clear that achieving optimal visibility requires looking beyond traditional practices and technologies. This is where global, crowdsourced testing takes center stage, illuminating blind spots that Last Mile Monitoring can miss.
A tried and true technique, Last Mile Monitoring provides invaluable insights into the quality and accessibility of services by collecting data from ISP endpoints. This enables a fairly accurate representation of your customer’s bandwidth experience, helping you identify and resolve network connectivity issues swiftly.
However, Last Mile Monitoring is not without its caveats. For one, achieving broad network coverage necessitates forming agreements with multiple ISPs, which can quickly become expensive and complex to manage. More significantly, while it offers visibility into the connectivity journey up to the customer’s home or business, it fails to extend this insight to the user’s device. And as such, crucial information about your customer’s true end-to-end experience can slip through the gaps.
In contrast, Crowdsourced Testing extends its reach all the way to the end user’s device, providing a far more holistic view of your customer’s experience. With an army of real-world testers, it captures a diverse range of metrics that Last Mile Monitoring simply cannot. From the type of device and operating system to the browser and network they are on, every potential customer scenario can be evaluated.
One of the remarkable benefits of Crowdsourced Testing is its ability to tap into a much larger base of testers. With millions of potential testers around the world, it offers an expansive coverage that far surpasses the network diversity achievable through agreements with ISPs. This expanded tester base also results in the ability to vastly increase the monitorable elements within your networking stack, which when effectively utilized, can uncover unexpected trends and hidden opportunities.
Finally, Crowdsourced Testing brings affordability and scalability to the table. It liberates businesses from expensive ISP agreements, and its pay-per-test model makes it a scalable solution that can accommodate both small businesses and large enterprises.
In essence, while Last Mile Monitoring is a powerful tool in its own right, Crowdsourced Testing takes things a step further, capturing the intricate nuances of your customer’s true end-to-end experience. By offering a broader and more representative set of data points, Crowdsourced Testing empowers businesses to make more informed decisions and, ultimately, create a better user experience for their customers. As we look towards the future, it’s clear that the ability to look beyond the last mile and right up to the customer’s device will be key in setting the winners apart from the crowd.